SENTIMENT CLASSIFICATION
- Abdelrahman Elgammal - 900181126
- Abdelrahman Abouzeid - 900181004
Problem Statement
Our task is to build a fine-grained sentiment classification model using BERT to evaluate people’s perception of a product, service, review, etc...
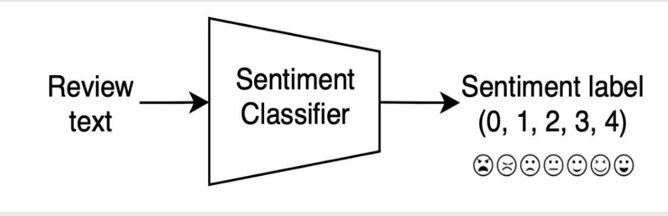
Dataset
We have used the ‘IMDb’ dataset on ‘paperswithcode’, which is a binary sentiment analysis dataset consisting of 50,000 reviews from the internet movie database (IMDb) labeled as positive or negative.
Other Datasets used for deploying the model:
SST5 - Stanford Sentiment Treebank (Fine-Grained Classification)
SST2 - Stanford Sentiment Treebank (Binary Classification
Input/Output Examples
From 0_10.txt from the IMDb Dataset "...The sign of a good movie is that it can toy with our emotions. This one did exactly that. ...".
--> This will be labled as Positive.
From 0_2.txt from the IMDb Dataset “...Once again Mr. Costner has dragged out a movie for far longer than necessary ...”.
--> This will be labled as Negative.
From 000157 from the SST5 Dataset “...Dense with characters and contains some thrilling moments ...”.
--> This will be labled as Neutral.

State of the art
state of the art accuracies on SST-5 and SST-2 Datasets.
Orignial Model from Literature
Fine-Grained sentiment Classification Model using BERT (Bidirectional Encoder Representation from Transformers).
Prior to the first stage involves some preprocessing on the text which includes things like canonicalization (which is basically to standardize the text by removing punctuation, making everything lowercase, etc.), tokenization (breaking down words into prefix, root, and suffix), and adding special tokens. Then this is given to first stage which is BERT embedding which we spoke about earlier which is used to compute the sequence embedding. This is then followed by a dropout regularization layer which makes sure that the model is sized correctly in terms of parameters, etc. to avoid underfitting/overfitting. It is finally followed by the softmax activation function which converts all the values into probabilities and then the highest value probability is the one selected as the outcome. The figure below shows the model structure.
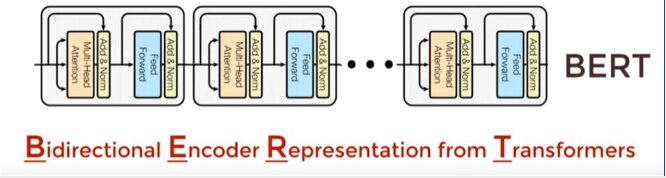
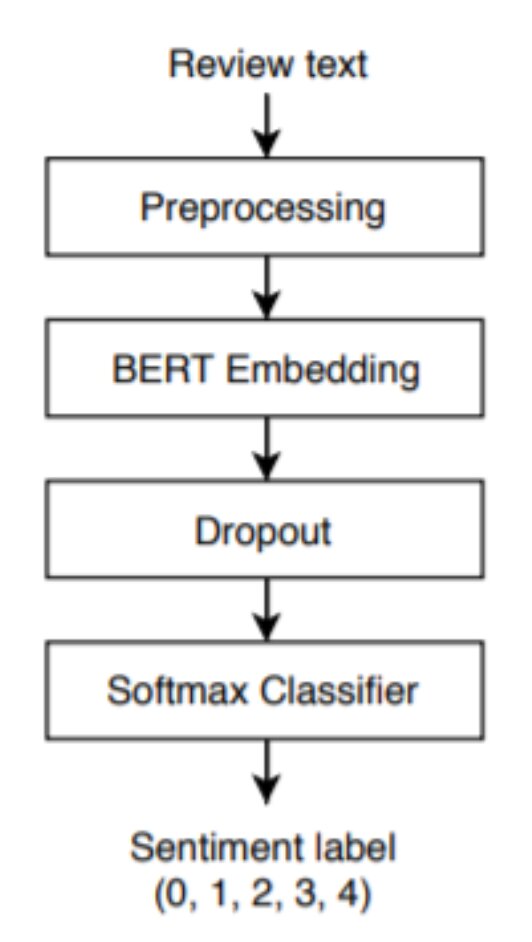
Proposed Updates
Update #1: deploying the model on IMDb dataset
We have deployed the model on IMDb dataset which required us to fully modify the data.py in the data preprocessing stage, changing the model from taking input as tree-based format to text 'uint8' format and training the model on 50,000 text reviews samples.
Update #2: Fine-tuning hyper-parameters
In this stage we have deployed the model on diffrent hyper-parametrs:
BERT-Base, BERT-Large,
Diffrent Batch sizes,
Diffrent number of epochs,
Freezing layers,
Diffrent optimizers & loss functions
And the best accuracies achieved was using the following hyper-parameters:
BERT-LARGE-uncased
Batchsize = 32
No. of epochs = 6
freezing layers = 0
optimizer = Adam
Loss Function = Cross-Entropy.
Results
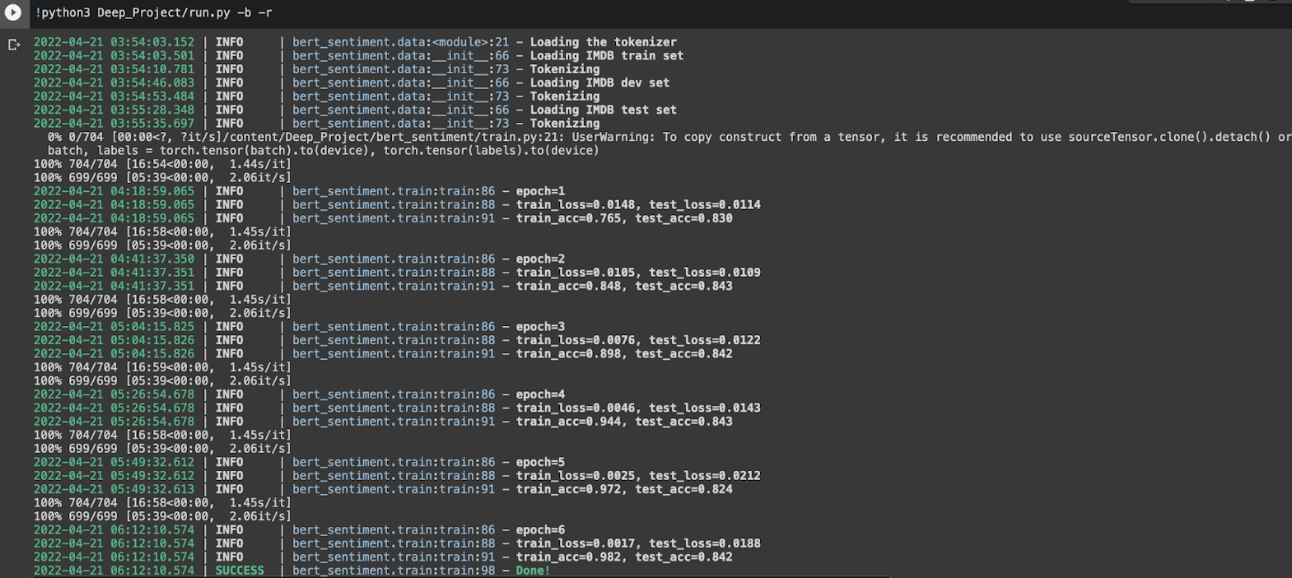
We have trained our model for 5-10 epochs on both BERT BASE and BERT LARGE which gave us some promising results reaching accuracies of ~84% on both BERT BASE and BERT LARGE.
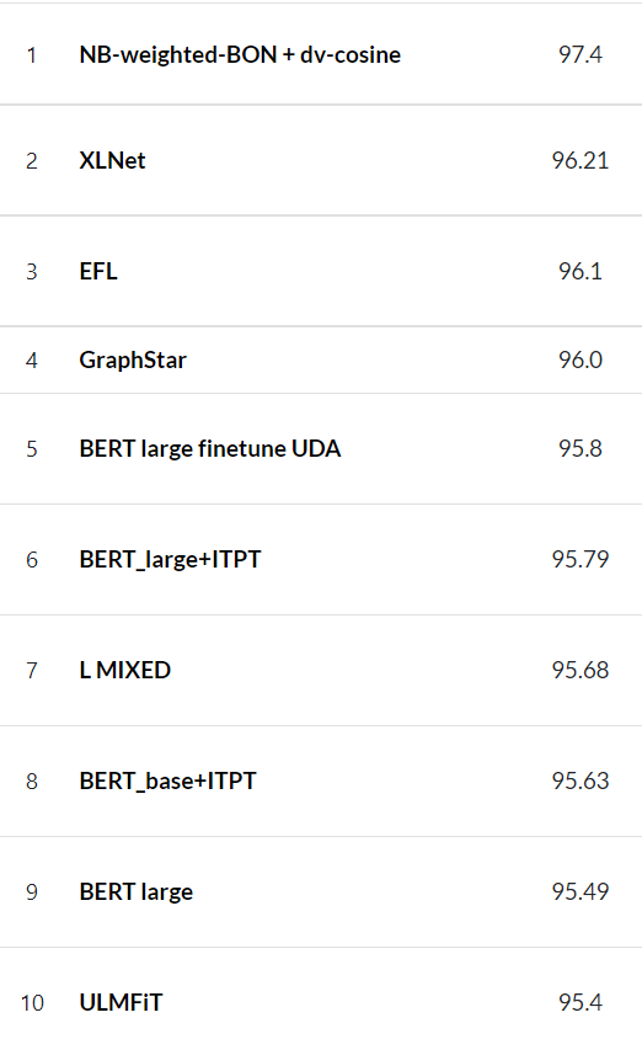
Although, this is not on par with the state-of-the-art results for models performing sentiment classification on the IMDb dataset which is as high as ~97% (refer to figure below).
Technical report
- Programming framework: pytorch
- Training hardware: colab
- Training time: 2.3 hours
- Number of epochs: 6 epochs
- Time per epoch: 23min.
- Number of training text reviews: 25,000
- Number of testing text reviews: 25,000
Conclusion
Final comments:
Overall, it is obvious that there are other models that are better for sentiment classification on the IMDb dataset. This can be due to our model being more adapted to the SST dataset, which can be resolved with hyperparameter tuning.
Due to its complexity, the model takes too much time in training, and we don’t have enough computing and memory resources. This makes hyperparameter tuning very difficult.
Future work:
Unfortunately, we were not able to implement the unsupervised learning section of our project and we want to continue working on that even after the course is done.
Further tune the hyper-parameters taking inspiration from similar models.
References
List all references here, the following are only examples